Naturgy — EDA y predicción
Cuatro años de electricidad horaria española (2015–2018): exploración, feature engineering y predicción del precio a 24 horas vista con XGBoost (V1 base + V2 con fundamentales day-ahead).
Un encargo ficticio de Naturgy planteado como proyecto final de máster. El mercado mayorista OMIE cierra su subasta a las 12:00, así que el objetivo es predecir el precio del día siguiente sin data leakage. Desde parquets de capa silver ejecuté el EDA completo, ingeniería de características (vectorización del viento, codificación cíclica sin/cos, festivos, lags, medias móviles) y entrené dos versiones de XGBoost con horizonte day-ahead: un modelo base autorregresivo (V1) y uno con predictores day-ahead alineados a la hora objetivo (V2). El año 2018 completo quedó reservado como test aislado, y tras corregir un par de data leaks ambas versiones quedan a la par.
Qué hace que funcione.
- 01
Eliminadas las columnas de generación real para evitar data leakage — el modelo solo usa previsiones day-ahead disponibles antes de la subasta OMIE de las 12:00.
- 02
Feature engineering sin VIF: vectorización del viento, codificación cíclica sin/cos, festivos + vísperas, lags [1h, 24h, 168h] y estadísticos de tendencia/volatilidad.
- 03
Dos versiones de XGBoost evaluadas sobre el año 2018 aislado (sin shuffle): V1 base autorregresivo (R² ≈ 0.71) y V2 con predictores day-ahead alineados a t+24 (R² ≈ 0.70). Tras corregir un par de data leaks en lags y medias móviles, ambos modelos quedan a la par: la autorregresión de precio ya capturaba casi toda la señal predecible.
— Contexto
Un proyecto final de máster planteado como encargo ficticio de Naturgy. El equipo global diseñó el pipeline de GCP (Cloud Storage → Dataproc/Spark → BigQuery → Vertex AI / Power BI). Mi parte fue el notebook analítico: tomar los parquets de capa silver y convertirlos en una predicción de precio defendible y sin trampas.
— El problema
El mercado mayorista español OMIE cierra su subasta diaria a las 12:00, fijando los precios de todo el día siguiente. Naturgy necesita saber hoy el precio de mañana. Si la predicción falla, la mesa de trading oferta a ciegas y la comercializadora asume pérdidas. El dataset incluía columnas de generación real y predicciones TSO que habrían filtrado el target — el trabajo empezó por eliminarlas.
El proceso, paso a paso.
- 01 Research
Elimina el data leakage antes que nada.
El dataset incluye columnas de generación real (solar, eólica, nuclear, carbón…) que en producción no estarían disponibles al predecir t+24. Eliminadas todas antes del EDA. Solo se conservan las previsiones day-ahead del operador (forecast solar, forecast wind, total load forecast) y el precio actual como base de lags — todo disponible la víspera.
- 02 Research
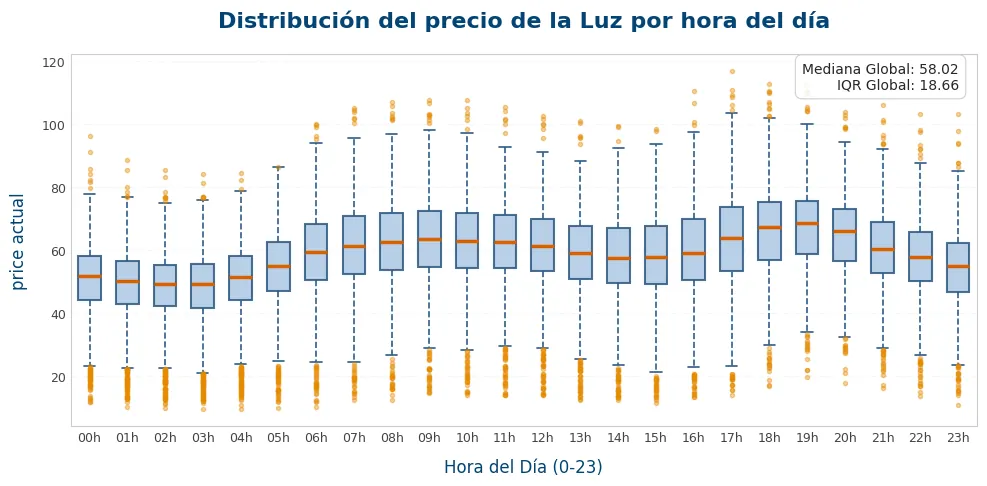
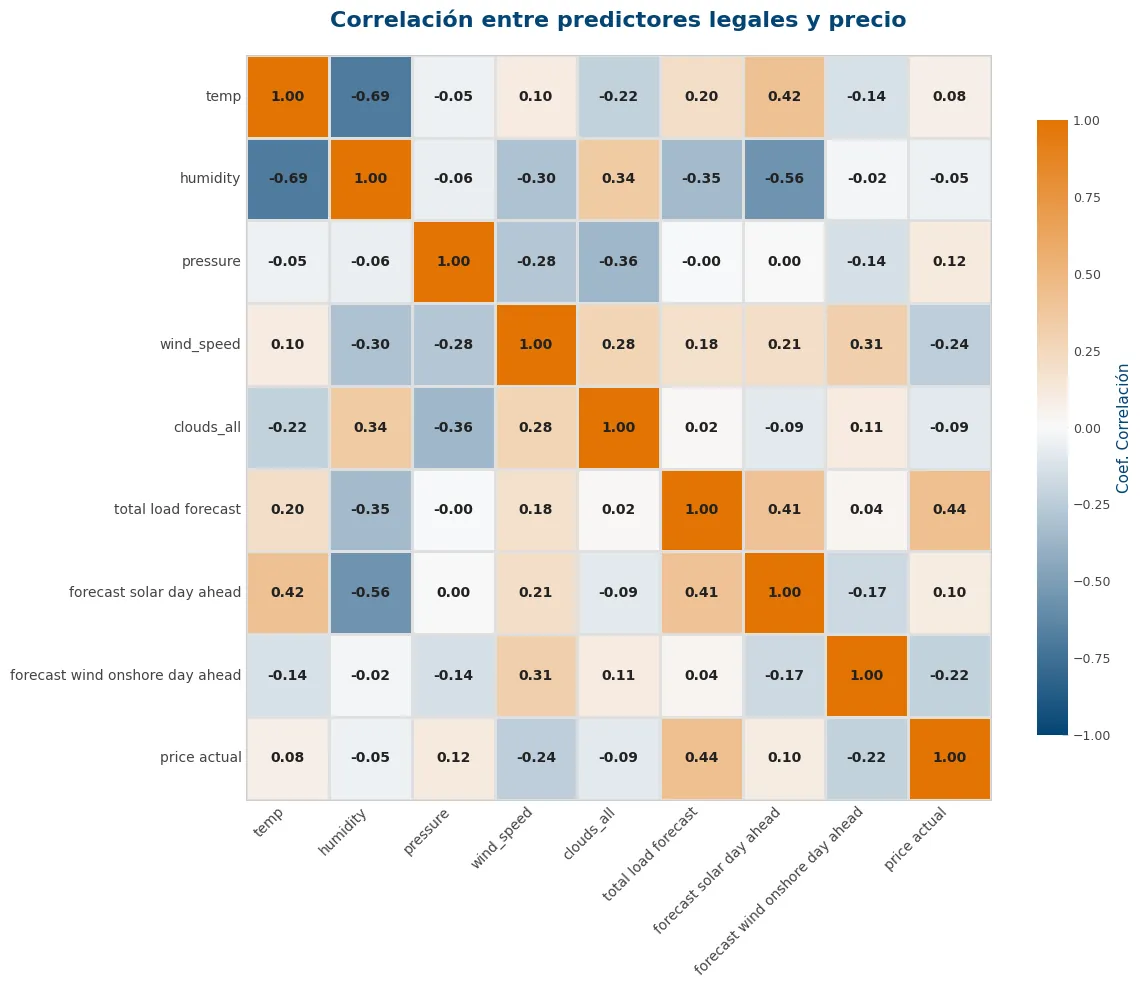
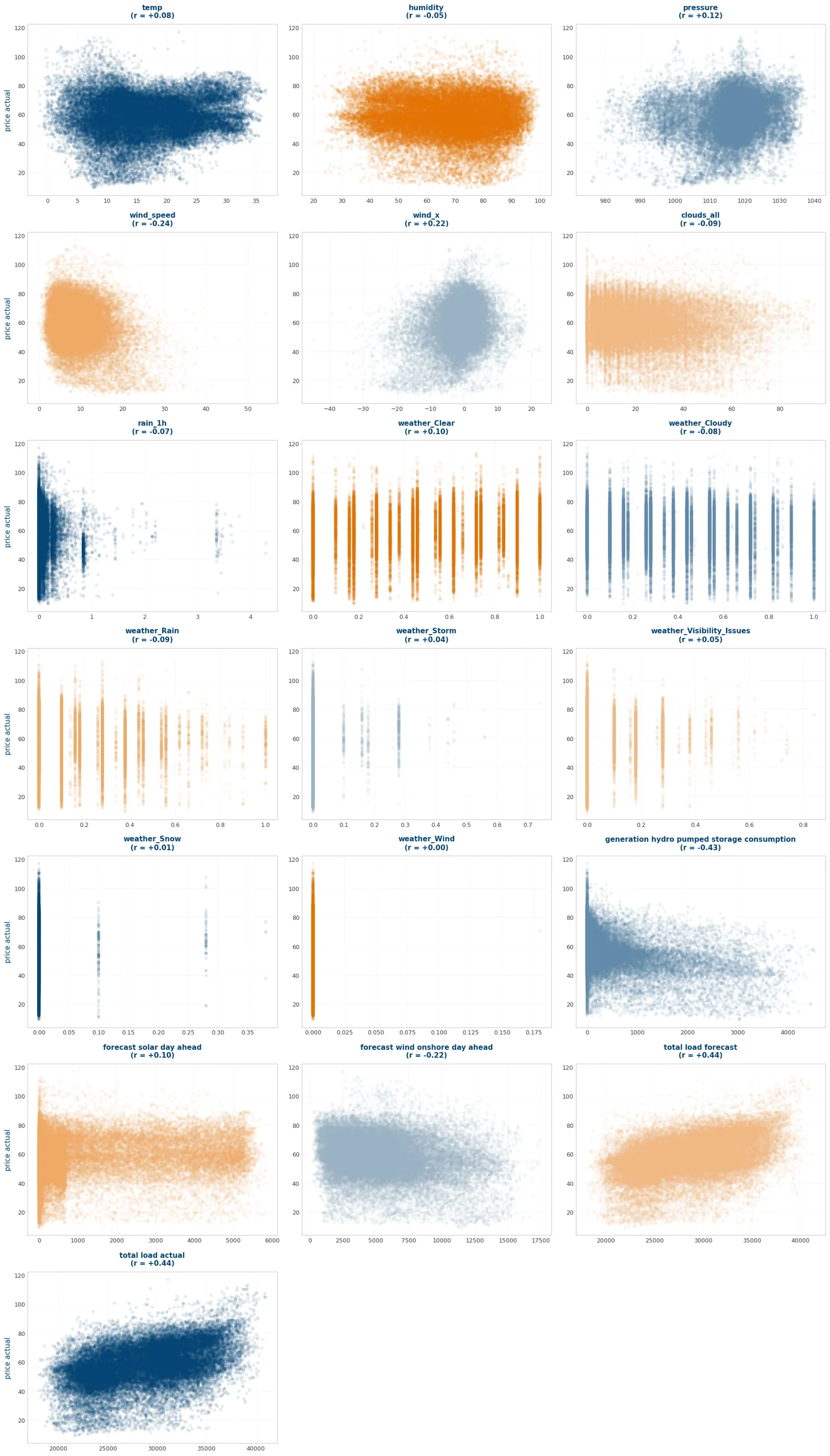
EDA — correlaciones, distribuciones y patrón diario del precio.
Correlación de cada variable frente al precio: hydro pumped storage consumption resulta el predictor más potente, confirmando que la gestión del bombeo es el driver oculto del precio. Distribución del precio por hora del día: picos claros a las 9h y 19h. Matriz de correlación climática: clouds_all captura la misma información que weather_Clear y weather_Cloudy — estas últimas se eliminan.
- 03 Build
Feature engineering orientado a series temporales.
Vectorización del viento a su componente este-oeste (wind_x) para respetar su naturaleza direccional sin duplicar información colineal. Pesos por ciudad (Madrid/Barcelona 28%, Sevilla 18%, Valencia 16%, Bilbao 10%) para ponderar el clima según demanda real. Codificación cíclica sin/cos de hora, día de semana y mes. Festivos nacionales 2015–2018 + vísperas + días hasta/desde festivo. Medias móviles y desviación estándar desplazadas 1h (sin fuga). Lags de precio y carga a [1h, 24h, 168h].
- 04 Model
XGBoost V1 — modelo base con horizonte day-ahead.
Target: precio dentro de 24 horas (shift(-24)). División cronológica: 2015–2017 como train+val, 2018 completo como test aislado. XGBoost con Pipeline de sklearn, StandardScaler, early stopping a 100 iteraciones. Resultado en validación: RMSE ≈ 5.49 €/MWh, MAE ≈ 3.84 €/MWh, R² ≈ 0.72. En el test aislado de 2018: R² ≈ 0.71.
- 05 Model
XGBoost V2 — predictores day-ahead alineados a la hora objetivo.
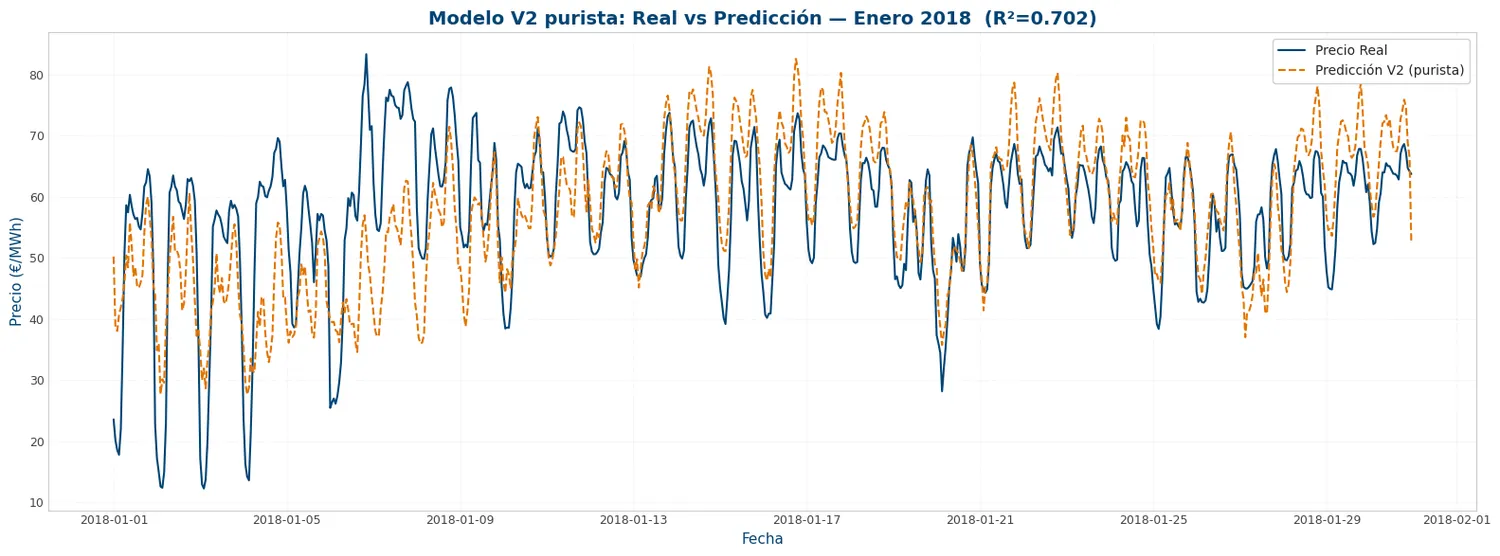
Añadidos predictores que son legítimamente conocidos el día anterior: previsiones de demanda, solar y eólica de la hora t+24, clima previsto (proxy de previsión meteorológica a 24h), demanda residual y ratio renovable. Mismo holdout de 2018. Resultado: R² ≈ 0.70 — a la par del modelo base. Al corregir dos data leaks (lags y medias móviles que se construían con horas no disponibles al cierre de las 12:00), la supuesta mejora desaparece: los fundamentales day-ahead no añaden señal sobre lo que los lags de precio ya capturan. La lección es metodológica, no de score.
- 06 Ship
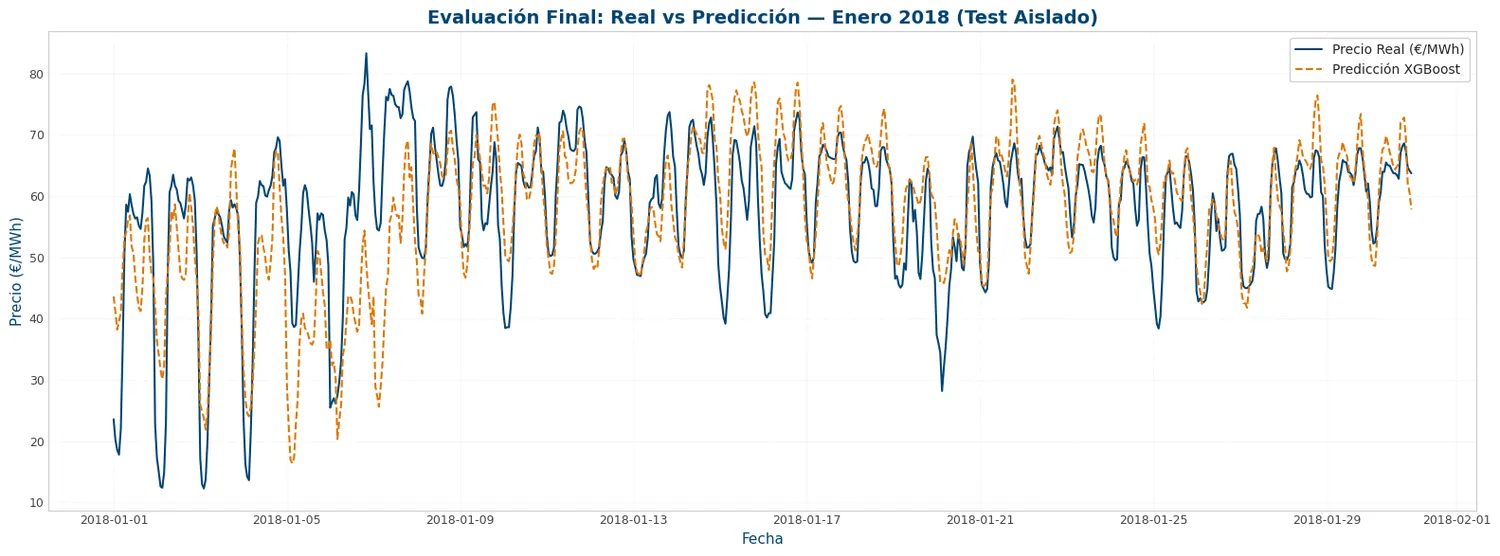
Evaluación final sobre el año 2018 completo reservado.
Gráficas actual-vs-predicho en el test aislado. Análisis de residuos: el modelo falla más en picos extremos de precio (eventos de mercado imprevisibles). Feature importance: precio lag-24h, precio lag-168h y la demanda residual son los drivers principales del V2. El notebook cierra con un veredicto escrito sobre las limitaciones del sistema eléctrico español en plena transición energética.
7 capturas, un producto.


Cifras, sin adornos.
- t+24h Horizonte de predicción — Day-ahead: precio del día siguiente antes de la subasta OMIE de las 12:00
- 2018 Año de test reservado — Cronológico — sin shuffle, sin fugas
- R² 0.70 XGBoost V2 (sin data leaks) — A la par del V1 base (R² ≈ 0.71) en el test aislado de 2018
- XGB V1 → V2 Dos versiones comparadas — V2 añade predictores day-ahead alineados a la hora objetivo
“La restricción del mercado es el diseño: predecir a t+24 sin ver lo que pasa a t+0.
” — Naturgy EDA — principio de trabajo